一切皆可转为
Markdown
完美支持 20+ 种文档格式、复杂单页应用网页(SPA)、以及高精度工业级图像 OCR 表格还原。本地优先处理,安全高效。
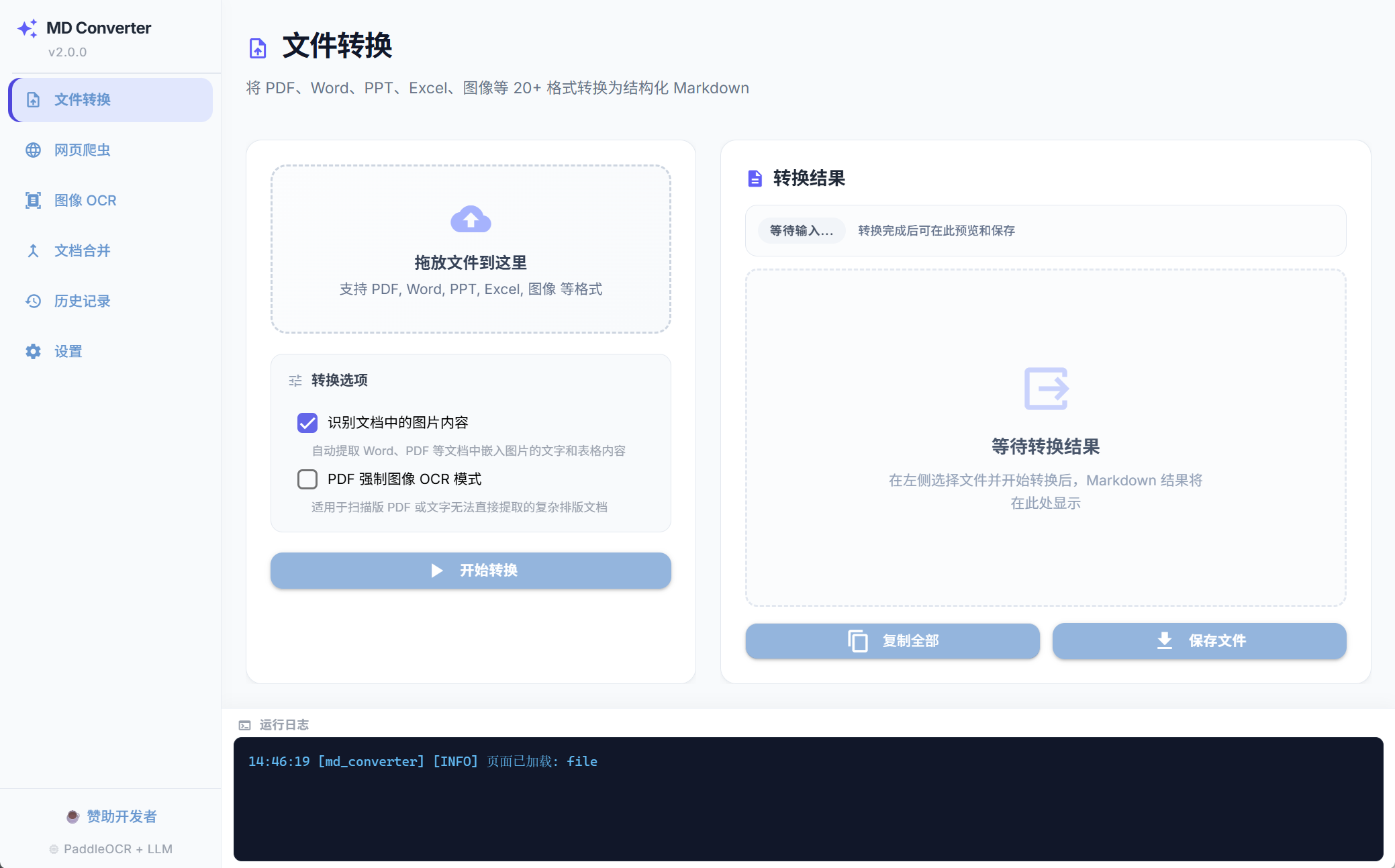
强大的核心引擎
不仅仅是转换器,更是您构建个人知识库的最强数据摄入管道
全能格式转换
支持 PDF, Word, PPT, Excel, HTML, 甚至音视频。内置微软 MarkItDown,自动提取 Word 文档中的嵌入图片并进行 OCR 识别,绝不遗漏任何细节。
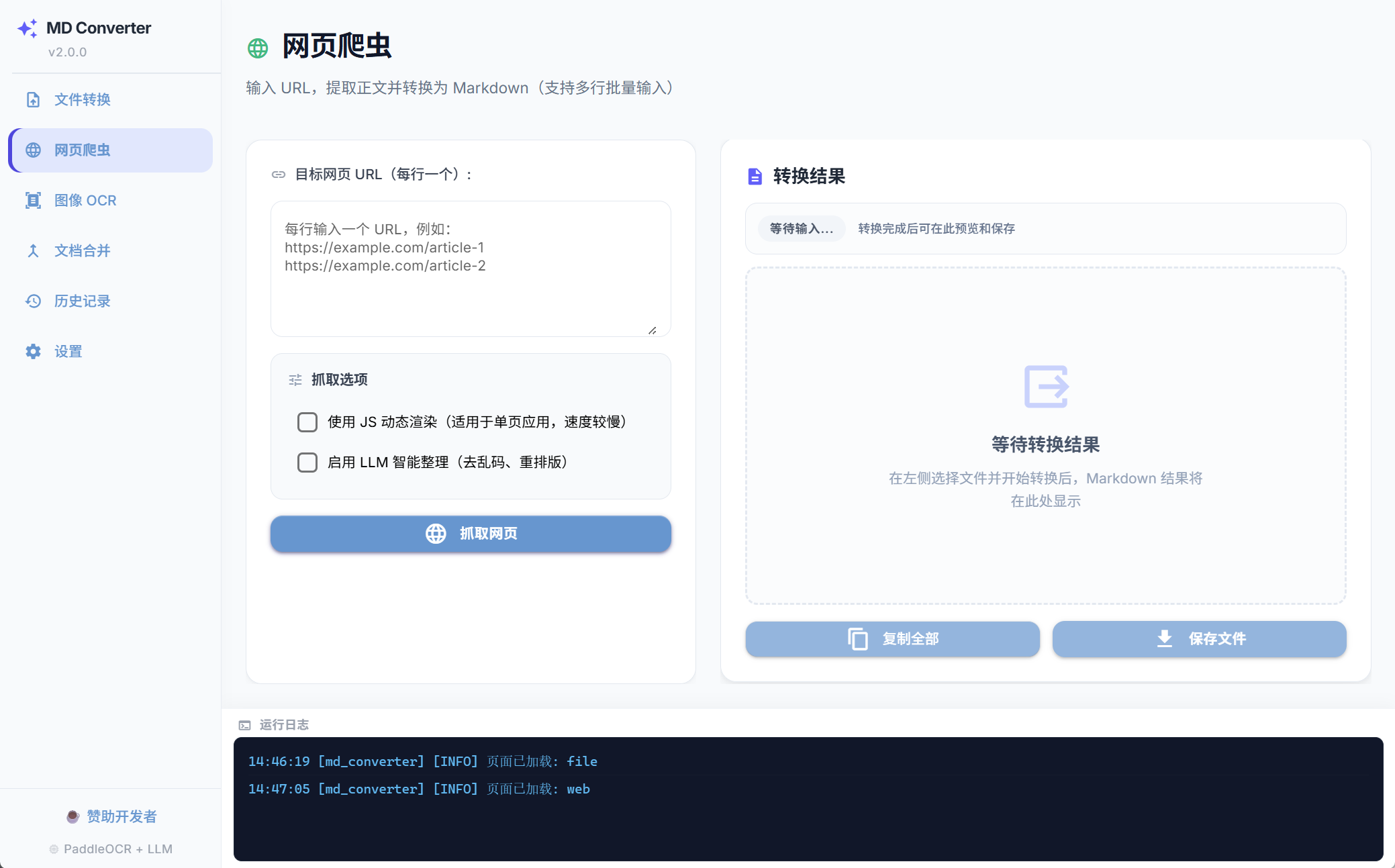
深度网页爬虫
穿透现代 SPA 单页应用的动态渲染(Playwright 无头浏览器支持)。智能去除广告和侧边栏噪音内容,仅保留最纯净的文章正文。
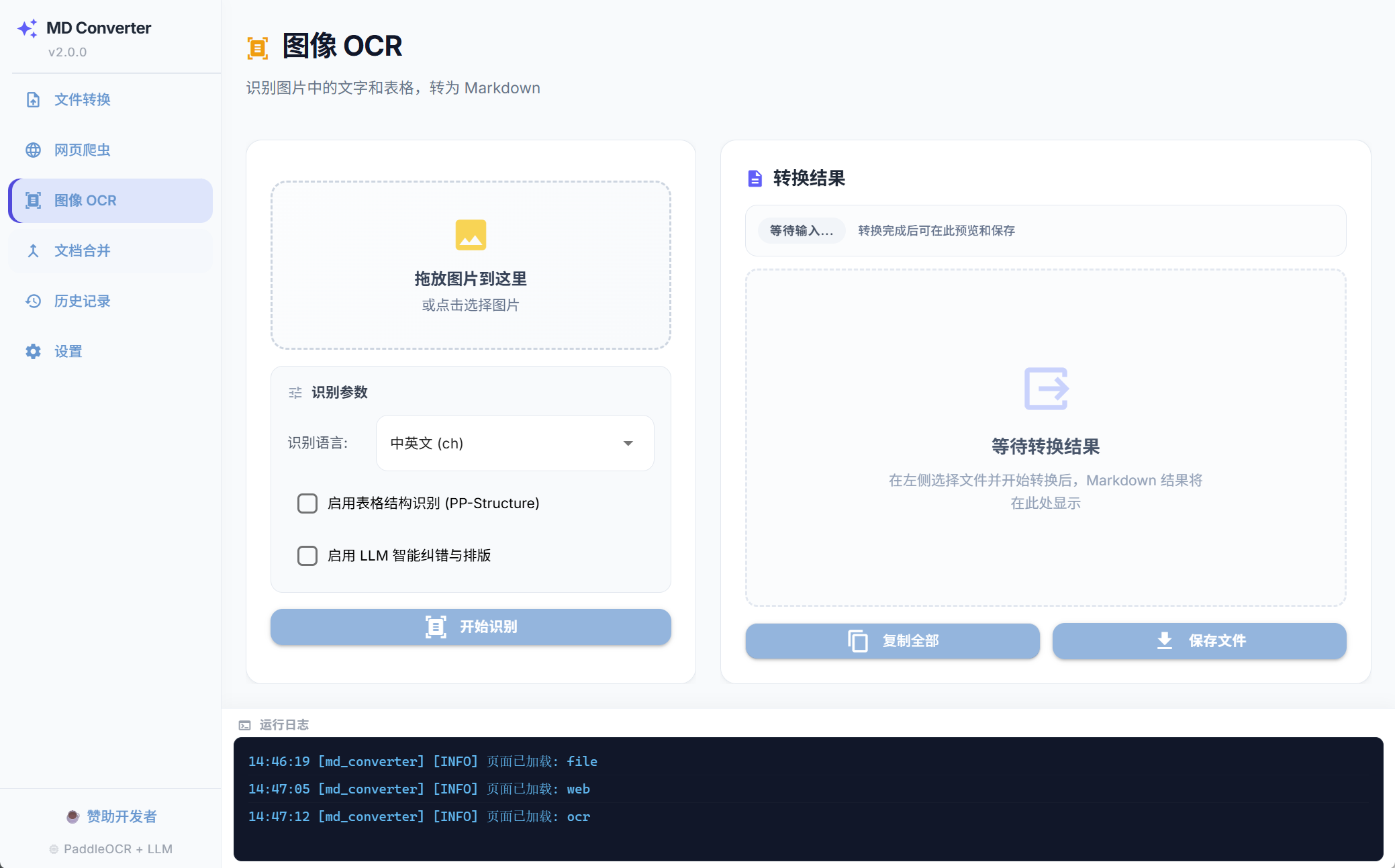
工业级 OCR & 表格还原
集成深度学习引擎 PaddleOCR 与 PP-Structure,支持多语种识别,完美还原极其复杂的表格结构,扫描版 PDF 轻松应对。
AI 智能润色
原生支持 OpenAI 兼容 API。可在转换完成后,自动通过大语言模型进行错别字修正、专业术语统一和智能版式优化。
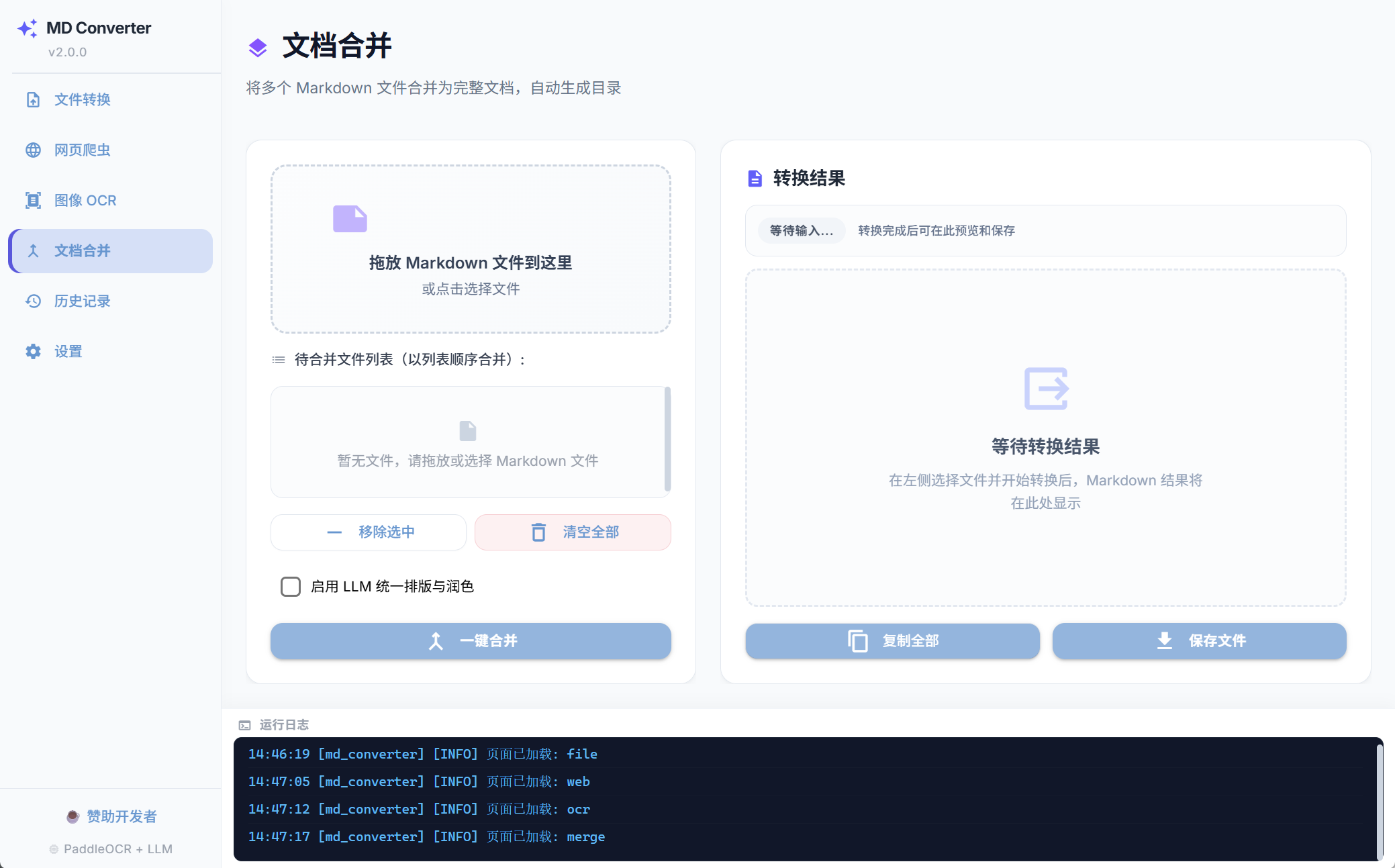
无缝文档合并
将零散的多个 Markdown 文件一键整合,自动生成全局 TOC 目录,并将引用的本地图片自动转换为 Base64 内联格式,方便分享。
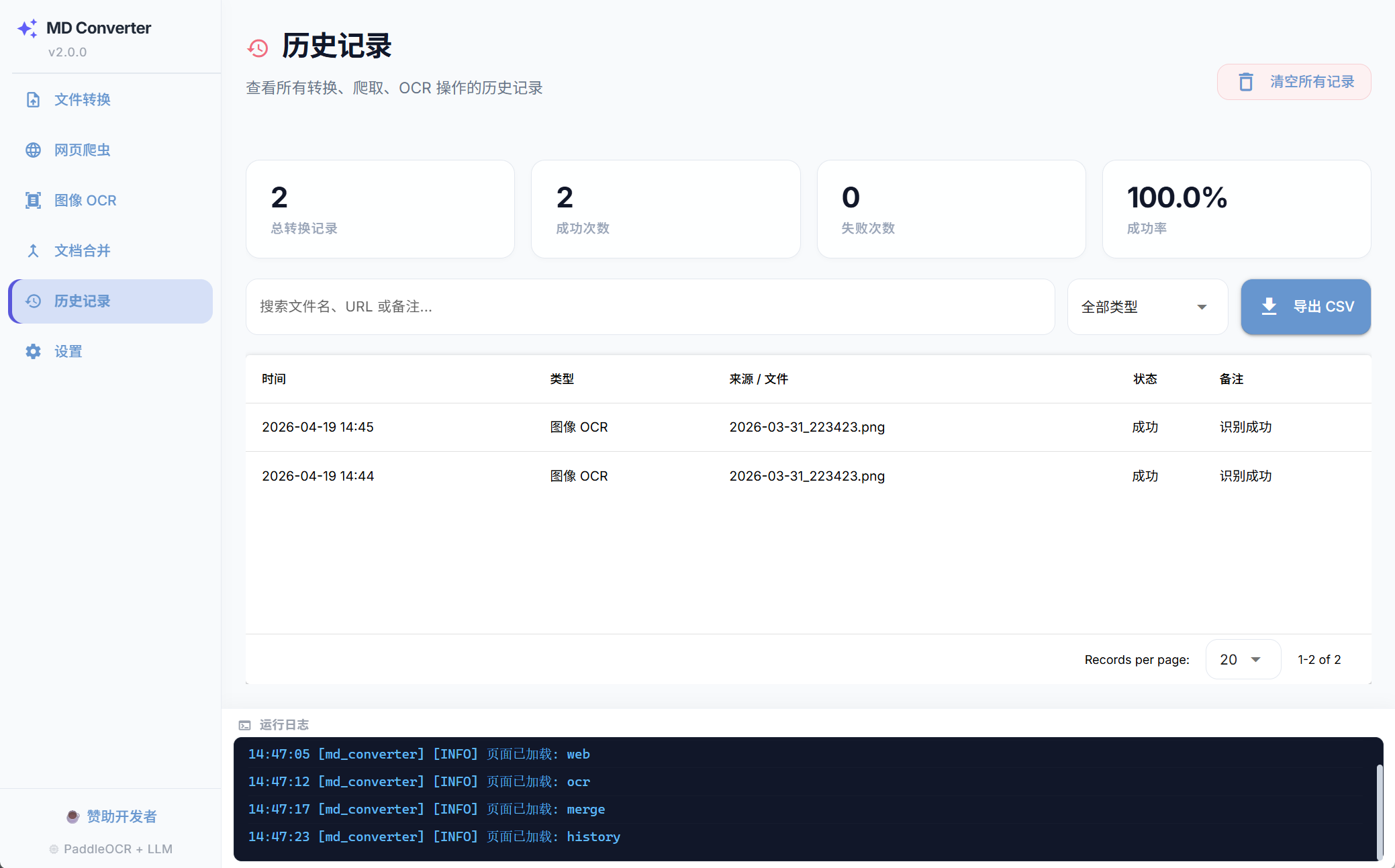
完整的历史追溯
内置 SQLite 数据库,全量记录所有操作历史、成功率统计和耗时分析。所有记录均可在应用内全文搜索,一键回溯您的数据摄入脉络。
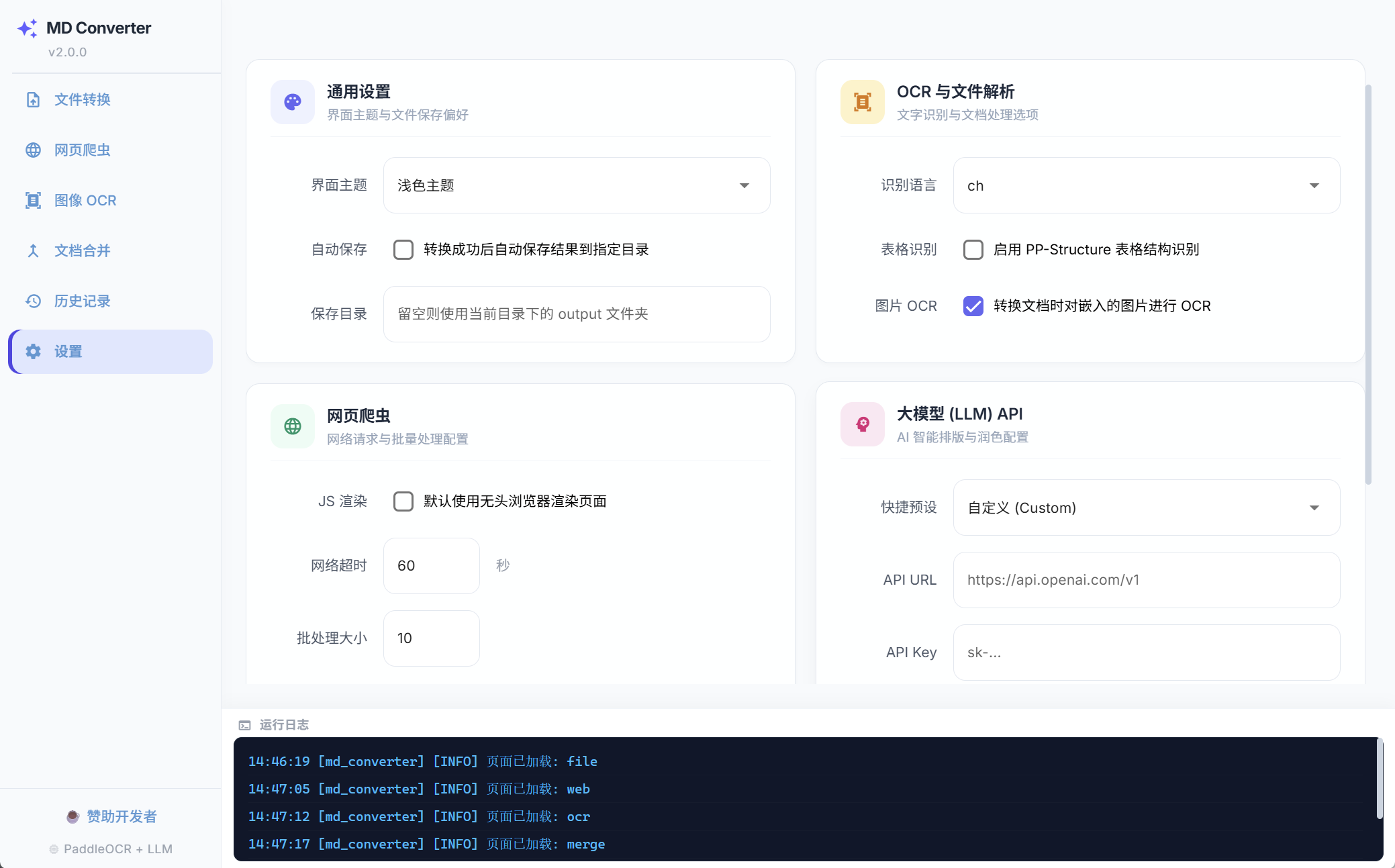
极致的本地交互体验
基于 NiceGUI 与 WebView 构建的现代化桌面应用界面
硬核技术底座
100% 隐私安全
文档转换、网页渲染、OCR 识别等核心处理流程完全在**本地运行**,没有任何内容会上传至未知服务器,绝对保障您的数据安全。
Magika 智能文件嗅探
接入 Google 开源的 Magika 深度学习模型,以毫秒级速度通过文件二进制签名识别超过 100 种文件类型,无惧文件后缀名被篡改。
异步高性能并发
底层采用 Python Asyncio + ThreadPoolExecutor 双擎架构,多任务处理互不阻塞,UI 界面永远保持丝滑流畅。